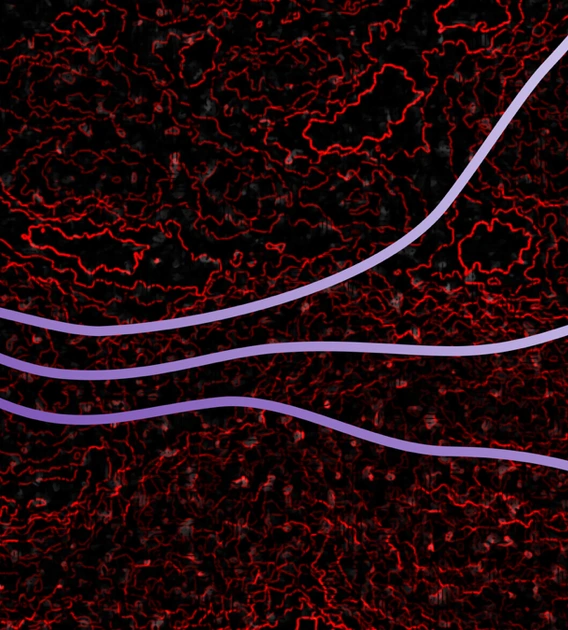
Today University of Arizona astronomer develops novel method to make AI more trustworthy A new technique helps artificial intelligence systems recognize when they don't know the answer, addressing "wrong-but-confident" AI outputs across science and society.
Nov. 17, 2025 Arizona Athletics and Casino Del Sol announce $60 million-plus stadium naming rights partnership The University of Arizona and Casino Del Sol, an enterprise of the Pascua Yaqui Tribe, announced a 20-year naming rights agreement for Arizona Stadium valued at more than $60 million, the largest such agreement in Big 12 Conference history.
Nov. 17, 2025 U of A expert leads process to codify the first global standard on Indigenous Peoples' data The standard, which advises scientists and professionals how to record provenance for data about and from Indigenous Peoples' nations, communities and territories, is the first of its kind and takes effect during Native American Heritage Month in the U.S.
Nov. 17, 2025 Precision Aging Network data release will open new pathways for healthy aging research University of Arizona researchers will release the first four years of data from a nationwide study on precision aging, ushering in a new era of discovery for brain health and longevity.
Nov. 12, 2025 U of A scientists recognized with prestigious NIH 'New Innovator' awards U of A researchers Shang Song and M. Maya Kaelberer each received the National Institutes of Health's prestigious New Innovator Award.
Nov. 12, 2025 TFTV ranked No. 4 public film school in The Wrap's 'Top 50 Film Schools' of 2025 The University of Arizona School of Theatre, Film & Television is ranked No. 4 among public film schools by The Wrap, which recently released its annual "Top 50 Film Schools in the U.S." list.
Nov. 10, 2025 College of Veterinary Medicine draws one of nation's largest applicant pools The American Association of Veterinary Medical Colleges lists the college as the third-most popular choice in the United States among up-and-coming veterinarians.
Nov. 5, 2025 How U of A students braved the summer sun to help communities become heat resilient More than 150 students across all three state universities have been involved in a Department of Energy program to help communities understand and respond to extreme heat. Their work, researchers said, was crucial to gathering data that will inform researchers' advice to city planners.
Nov. 5, 2025 University of Arizona receives $1M gift commitment from Steve Kerr to fund study abroad at the College of Humanities Kerr, an NBA champion, award-winning coach, social justice advocate, philanthropist and beloved Wildcat, says the time he spent living abroad changed his worldview.
Nov. 5, 2025 Arizona Athletics showcases national reach and university strength in Houston The annual Arizona Athletics Wildcat Club donor trip celebrated the University of Arizona's academic excellence, research leadership and championship culture.