Oct. 21, 2025 From posters to speeches, students test presidential skills in U of A contest The Pathway to the Presidency student competition challenges middle and high school students to craft campaign posters and speeches to celebrate the United States' 250th birthday.
Oct. 20, 2025 From gift to galaxy: Flandrau Science Center & Planetarium turns 50 Founded in 1975, Flandrau has inspired generations of curious minds with exciting planetarium shows, curiosity-quenching science exhibits, community programs and resources for teachers and students of all ages.
Oct. 16, 2025 Study finds humans outweigh climate in depleting Arizona's water supply University of Arizona researchers evaluate the impact of pumping on groundwater levels using data spanning millennia.
Oct. 16, 2025 Two U of A antiquities experts named members of the Institute for Advanced Study Eleni Hasaki, an expert on ancient Greek ceramics, and Irene Bald Romano, a scholar of Greek and Roman sculpture, will each spend a semester at the renowned institute in New Jersey.
Oct. 15, 2025 U of A President Garimella names Iler as general counsel University of Arizona President Suresh Garimella announced that he has selected Clifton "Cliff" Iler as the university's new general counsel.
Oct. 14, 2025 Karletta Chief named to inaugural endowed professorship in Indigenous resilience The Haury Professorship in Indigenous Resilience advances the university's world-class Indigenous environmental resilience research, education and outreach.
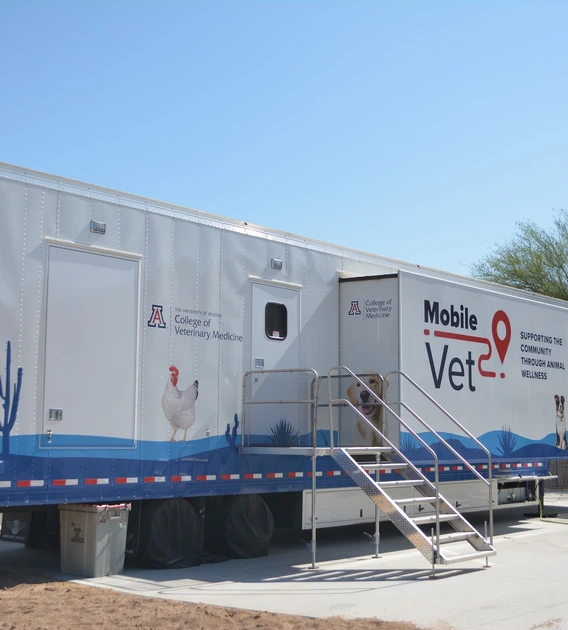
Oct. 13, 2025 Veterinary Medicine students partner with Purina to provide healing and hope to domestic violence survivors The initiative involves the College of Veterinary Medicine's mobile surgical unit, a 53-foot facility capable of supporting free wellness exams, screenings, vaccinations and other proactive treatments.
Oct. 13, 2025 Celebrating U of A faculty brilliance at the 2025 Luminaries Awards The event honors faculty achievements and the visionaries who push boundaries and set new standards of excellence.
Oct. 10, 2025 A collective approach to help vulnerable people survive extreme heat The Heat and Health Resilience Innovation Consortium will help protect those most at risk of health threats brought by high temperatures.
Oct. 9, 2025 U of A ranked No. 1 in the Southwest and recognized as a top 25 public university by Times Higher Education Times Higher Education highlighted the university's strengths in research quality and physical sciences in its latest ranking of the world's top universities.